跨团队数据交付的沟通小记
这是学习笔记的第 2387篇文章

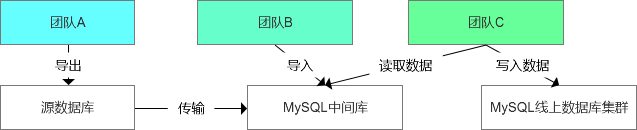
本来这是一件看起来很简单的事情,但是在沟通中也收到了团队A交付的数据样本,主要存在2类问题:
1)数据格式和MySQL线上的数据格式差异很大,比如源端是2个字段,其中包含有JSON字段,线上是完全结构化的数据存储,可能有5个字段,也就是字段不是一一映射的模式
2)因为包含JSON数据,所以导出数据的时候,有些数据因为格式的差异,会有跨多行的情况。
3)导出的csv文件中分隔符是逗号,在JSON中本身也存在大量的逗号,所以导入的过程中存在很多潜在的风险和不确定性。
所以就上面的问题我们进行沟通的时候,就会出现所谓的边界,即有些事情好像怎么做都可以,多做一点,少做一点都可以,但是大家都更倾向于少做一些,其实也可以理解,我们回归问题的本质,看看影响是什么?
团队A: 如果导出数据时自带一些逻辑处理,其实是有一些业务倾入性的,而且很难保证额外的逻辑处理一定满足期望
团队B: 数据的质量难以保证,因为难以衡量团队A导出的数据是否完整,准确,同时又无法保证团队C能够合理的使用数据,因为团队B的工作就是导入数据,但是数据如何有问题,还是需要找团队A确认,是一种黑盒操作
团队C: 如果上游的数据存在问题,那么团队C后续的工作就可能丢数据
所以我没有把这句话说满,而是做了两种假设:
1)既然团队B的工作就是数据导入,而且数据导入失败还得需要团队A的支持,团队A是否可以直接完成导出导入的工作?团队A的直接回答就是不同意
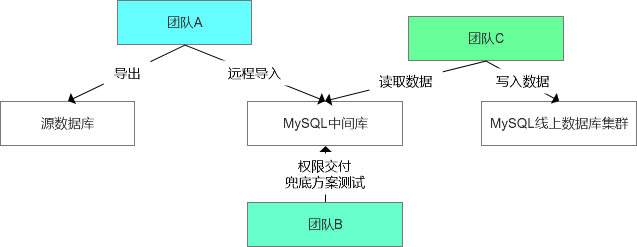
2)团队A既然不同意这种处理方案,如果从全局来看,是否存在一种可能,即团队C直接从源库读取数据,然后写入中间库中,后续从中间库的处理模式和原计划保持一致?因为这种方案从全局来看都是团队C来一手控制,而且通过应用程序直接读取看起来也比较合理。 整体的方案类似下面的形式:
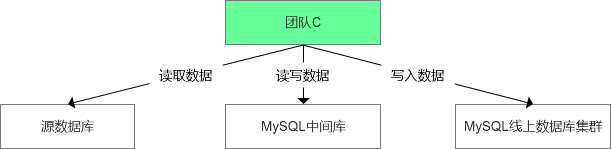
团队C想了下说,对啊,这也是一种可选方案,从应用层面来说,还是比较可控的,可能迁移的过程中需要控制频度和批次数量。
这个时候团队A开始有些担心了,因为团队C读取数据的时间比较长,按照当前的数据量可能需要好几天,而这个过程中团队C尤其需要注意频度和批次数量,否则可能会在一定程度上影响现有的数据服务负载等。
所以这个时候团队A开始动摇了自己的方案,反而更支持刚建议的方案,即从源端导出导入的操作,因为这样一类操作是运维侧相对可控的,而且导出导入的过程也是相对比较快的,比如通过程序批次的读取可能每秒钟1000条,但是通过加载csv的方式可能就会直接提升好几倍的效率。
折中后的方案如下:
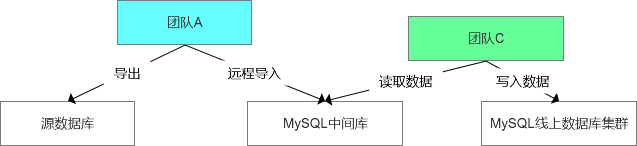
到了这个时候就算是一种比较合理的数据交付状态了,但是我所在团队B不是偷懒,而是需要在事后做如下的补充测试:
1)csv文件中存在JSON跨行的情况下,数据导入的换行分隔符配置和测试
2)csv存储引擎是否支持包含JSON数据的格式,如果可以的话,这个事情反而就更简单了。
所以表面上看起来我们是偷懒了,但是从全局来看,整个执行过程是相对可控的,而且我们的后备方案还是在同步测试中,一旦出现不可控的情况,我们的支持和后备方案就可以及时进行修正。
这也是我希望的一种跨团队数据交付中需要的一些思考,从本质来看,最怕出现的情况则是,每个人都没有错,但是结果却不理想,所以我个人式更推崇在不同的场景中应该如何变通。
各大平台都可以找到我
-
微信公众号:杨建荣的学习笔记 -
Github:@jeanron100 -
CSDN:@jeanron100 -
知乎:@jeanron100 -
头条号:@杨建荣的学习笔记 -
网易号:@杨建荣的数据库笔记 -
大鱼号:@杨建荣的数据库笔记 -
腾讯云+社区:@杨建荣的学习笔记
原创热文:
QQ群号:763628645
QQ群二维码如下, 添加请注明:姓名+地区+职位,否则不予通过
